Multi RenderTarget을 이용한 GBuffer 렌더링
1. 문제
DeferredShading을 위해 GBufferA, B, C를 드로우를 하려 했는데 기존의 ForwardShading처럼 RenderTarget을 바인딩하면 GBuffer 드로잉에만 드로우 콜이 '오브젝트 수 x 3'이 된다. 오브젝트당 한번의 드로우 콜로 GBuffer를 처리하여 드로우콜 수를 줄이고 싶었다.
2. 시도
기존에 픽셀 셰이더를 작성할때 아래와 같이 시멘틱을 붙이는 걸 볼 수 있다.
float4 PS() : SV_TARGET0
이를 통해, SV_TARGET이 0이상의 숫자로 여러개를 가질 수 있음을 추측할 수 있다.
예상대로, 멀티 렌더타겟이라는 방식이 존재했고, 이를 통해 GBuffer를 드로우 하도록 한다.
먼저 PipelineStateObject를 만들때 다음과 같이 렌더타겟의 수와 포맷을 설정해 준다.
GBufferPassPipelineStateDesc.NumRenderTargets = 3;
GBufferPassPipelineStateDesc.RTVFormats[0] = mGBuffers->GetFormat();
GBufferPassPipelineStateDesc.RTVFormats[1] = mGBuffers->GetFormat();
GBufferPassPipelineStateDesc.RTVFormats[2] = mGBuffers->GetFormat();
그 다음, 렌더 타겟들을 바인딩 해 준다. 바인딩은 공식 문서에 따르면 두가지 방법으로 할 수 있다.
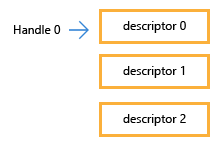
첫번째 방법은 바인딩하려는 렌더타겟들이 힙내에서 연속적으로 있을 경우 세번째 인자(RTsSingleHandleToDescriptorRange)를 true로 해주고 아래와 같이 작성할 수 있다.
D3D12_CPU_DESCRIPTOR_HANDLE GBufferARtv = mGBuffers->GetRTV("GBufferA", 0);
D3D12_CPU_DESCRIPTOR_HANDLE GBufferDsv = mGBuffers->GetDSVHeap()->GetCPUDescriptorHandleForHeapStart();
CommandList->OMSetRenderTargets(3, &GBufferARtv, true, &GBufferDsv);
이경우 렌더타겟이 아래 사진과 같이 묶이게 된다
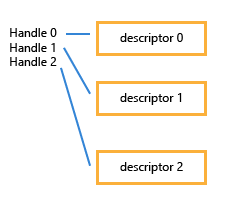
두번째 방법은 렌더타겟의 힙내 위치랑 관계없이 작성할 수 있다.
D3D12_CPU_DESCRIPTOR_HANDLE GBufferARtv = mGBuffers->GetRTV("GBufferA", 0);
D3D12_CPU_DESCRIPTOR_HANDLE GBufferBRtv = mGBuffers->GetRTV("GBufferB", 0);
D3D12_CPU_DESCRIPTOR_HANDLE GBufferCRtv = mGBuffers->GetRTV("GBufferC", 0);
D3D12_CPU_DESCRIPTOR_HANDLE Rtvs[] = { GBufferARtv, GBufferBRtv, GBufferCRtv };
D3D12_CPU_DESCRIPTOR_HANDLE GBufferDsv = mGBuffers->GetDSVHeap()->GetCPUDescriptorHandleForHeapStart();
CommandList->OMSetRenderTargets(_countof(Rtvs), Rtvs, true, &GBufferDsv);
이경우 렌더타겟은 아래 사진과 같이 묶이게 된다.
마지막으로, 픽셀 셰이더는 아래와 같이 적용한다. SV_Target 시멘틱을 0~2까지 설정해 준다.
void MainPS(
in float4 PosH : SV_Position,
in float3 NormalW : NORMAL,
in float2 TexC : TEXCOORD,
out float4 GBufferA : SV_Target0,
out float4 GBufferB : SV_Target1,
out float4 GBufferC : SV_Target2
)
{
[...]
}
3. 결과
- GBuffer 드로우 콜을 1/3으로 감소